
GPT-5, Explained

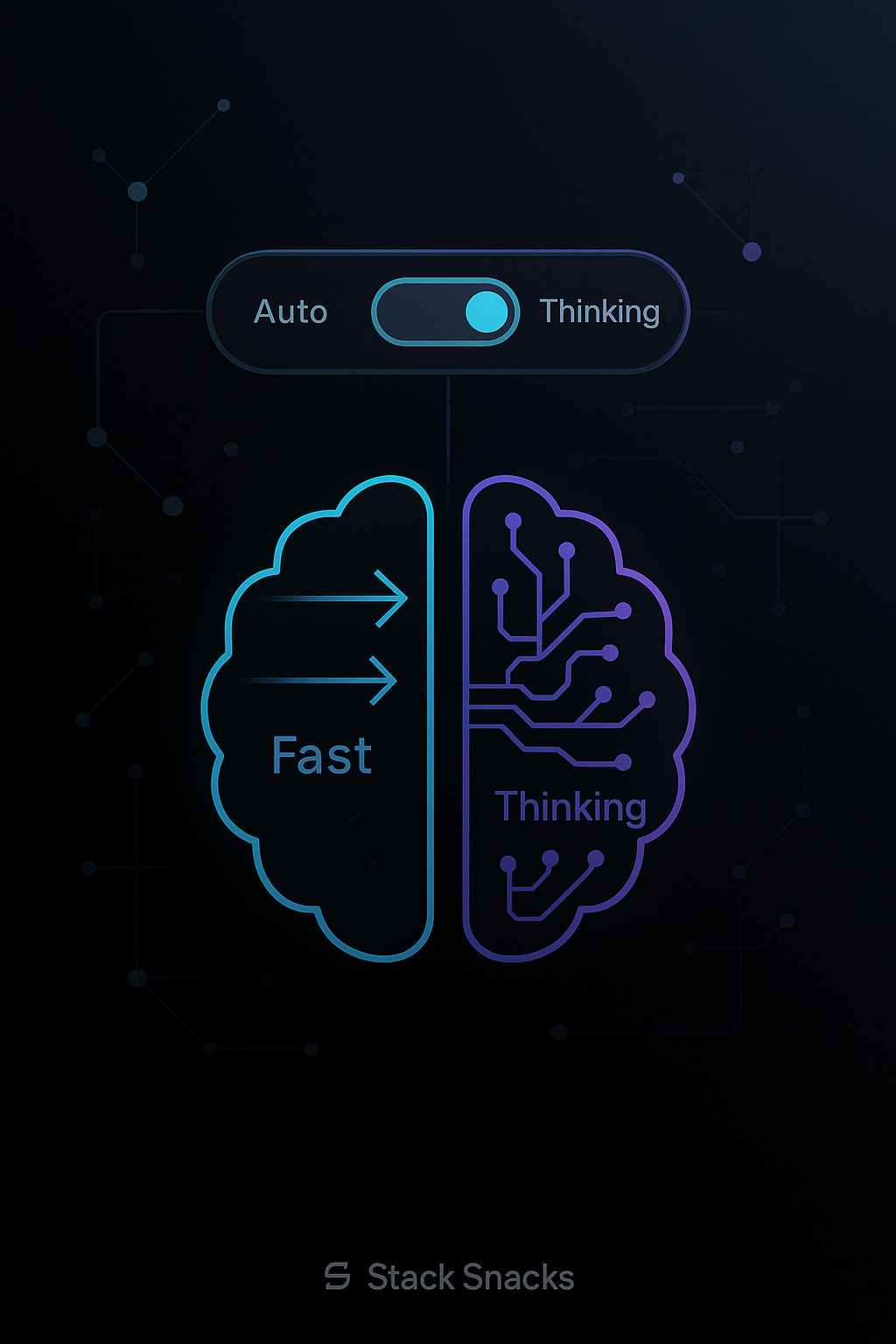
“Hey there, Happy Tuesday! 👋 In this snack-sized issue, we are going over the GPT 5 release and some of our earlier thoughts.
GPT-5 Is Out
The day we've all been waiting for is here. I can't remember the last time I was so excited about a product launch that I added it to my calendar to watch the livestream. The consensus is that GPT-5 operates different…
Keep reading with a 7-day free trial
Subscribe to Stack Snacks to keep reading this post and get 7 days of free access to the full post archives.